AI POD Reference Architectures
NVIDIA Certified GPU-accelerated hardware clusters for AI & HPC at scale
Scan AI, as a leading NVIDIA Elite Solution Provider, can deliver a variety of enterprise infrastructure architectures. This include NVIDIA EGX, HGX or DGX servers at their centre, known as PODs. These reference architectures combine industry-leading NVIDIA GPU compute with AI-optimised flash storage from a variety of leading manufacturers and low latency NVIDIA Networking solutions, in order to provide a unified underlying infrastructure on which to accelerate AI training whilst eliminating the design challenges, lengthy deployment cycle and management complexity traditionally associated with scaling AI infrastructure.
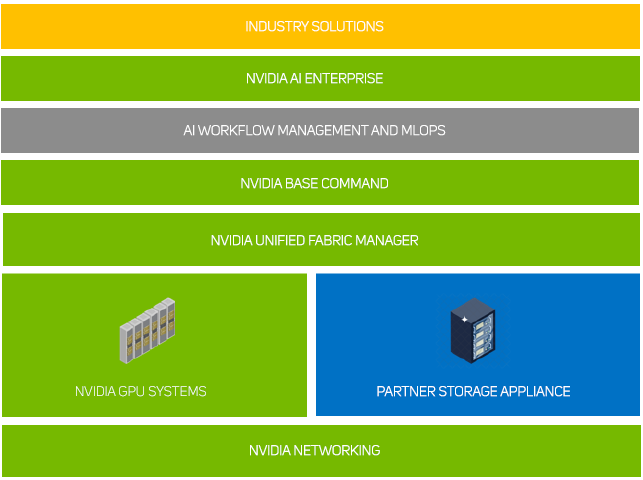
Although there is a vast variety of ways in which each POD infrastructure solution can be configured, there are four main architecture families - a Scan POD, based on NVIDIA EGX and HGX server configurations; an NVIDIA BasePOD including made upof 2-40 DGX H100, H200 or B200 appliances; an NVIDIA SuperPOD consisting of up to 140 DGX H100, H200 or B200 appliances centrally controlled with NVIDIA Unified Fabric Manager; and an NVIDIA DGX GB200 NVL72 Exascale appliance designed exclusively for LLMs and generative AI. All these infrastructures then connect to a choice of enterprise storage options linked together by NVIDIA Networking switches. Click on the tabs below to explore each solution further.
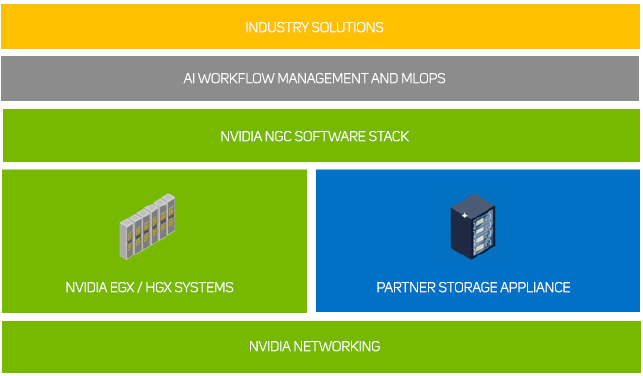
The Scan POD range of reference architectures are based around a flexible infrastructure kit list in order to deliver cost effective yet cutting-edge AI training for any organisation. A Scan POD infrastructure consists of NVIDIA EGX or HGX servers - starting at just two nodes - connected via NVIDIA Networking switches to a choice of NVMe storage solutions. This can then complemented by Run:ai Atlas software and supported by the NVIDIA GPU-optimised software stack available from the NVIDIA GPU Cloud (NGC).
Scan POD Servers
At the heart of a Scan POD architecture is either an NVIDIA-certified EGX or HGX GPU-accelerated server built by our in-house experts at 3XS Systems.

3XS EGX Custom AI Servers
Up to 8x NVIDIA professional PCIe GPUs
Up to 2x Intel Xeon or AMD EPYC CPUs
Up to 2TB system memory
NVIDIA ConnectX NICs / Bluefield DPUs - Ethernet or InfiniBand
Air or Liquid Cooling

3XS HGX Custom AI Servers
Up to 8x NVIDIA SXM4 GPUs
2x Intel Xeon or AMD EPYC CPUs
Up to 2TB system memory
NVIDIA ConnectX NICs / Bluefield DPUs - Ethernet or InfiniBand
Air or Liquid Cooling
Workload Management
The EGX and HGX systems are managed using Run:ai cluster management software to enable not only scheduling and orchestration of workloads, but also virtualisation of the PODs GPU resource. Run:ai allows intelligent resource management and consumption so that users can easily access GPU fractions, multiple GPUs or clusters of GPUs for workloads of every size and stage of the AI lifecycle. This ensures that all available compute can be utilised and GPUs never have to sit idle.

Scan POD Networking
Scan POD architectures can be configured with a choice of network switches, each relating to a specific function within the design and whether InfiniBand, Ethernet or both are being utilised.

NVIDIA QM9700 Switch
NVIDIA QM9700 switches with NDR InfiniBand connectivity link to ConnectX-7 adapters. Each server system has dual connections to each QM9700 switch, providing multiple high-bandwidth, low-latency paths between the systems.

NVIDIA QM8700 Switch
NVIDIA QM8700 switches with HDR InfiniBand connectivity link to ConnectX-6 adapters. Each server system has dual connections to each QM8700 switch providing multiple high-bandwidth, low-latency paths between the systems.

NVIDIA SN4600 Switch
NVIDIA SN4600 switches offer 64 connections per switch to provide redundant connectivity for in-band management. The switch can provide speeds up to 200GbE. For storage appliances connected over Ethernet, these switches are also used.

NVIDIA SN2201 Switch
NVIDIA SN2201 switches offer 48 ports to provide connectivity for out-of-band management. Out-of-band management provides consolidated management connectivity for all components in the Scan POD.
The Scan POD topology is flexible when it comes to configuration and scalability. Server nodes and storage appliances can be simply added to scale the POD architecture as demand requires.

Scan POD Storage
For the storage element of the Scan POD architecture, we have teamed up with PEAK:AIO to provide AI data servers that deliver the fastest AI-optimised data management around. PEAK:AIO’s success stems from understanding the real-life values of AI projects - making ambitious AI goals significantly more achievable within constrained budgets while delivering the perfect mix of the performance of a parallel filesystem with the simplicity of a simple NAS, all within a single 2U server. Furthermore, PEAK:AIO starts as small as your project needs, and scales as you need, removing the traditional requirement to over invest in storage at the onset. Additionally, a longstanding complication within high performance storage has been the need for proprietary drivers which can cause significant disruption and worse within typical AI projects when OS or GPU tools are updated. PEAK:AIO is fully compatible with modern Linux kernels, requiring no proprietary drivers.
 LEARN MORE
LEARN MORE
Secure Hosting
Accommodating a Scan POD architecture may not be possible on every organisations premises, so Scan AI has teamed up with a number of secure hosting partners with UK and European based datacentres. This means you can be safe in the knowledge that the location that houses your infrastructure is perfect to manage a Scan POD infrastructure and accelerate your AI projects.